Adventures in Reinventing the Wheel
A few days ago, one of my friends posted this status on Facebook, and it got me thinking: how could I test a hypothesis like this? Supposing I were to use GDP per capita as a measure of affluence, I would simply have to compare it to a measure of linguistic diversity, and compute the correlation coefficient.
But does such a measure of linguistic diversity exist? I wasn't aware of one, so I decided to come up with my own, which I would call the Linguistic Diversity Index (LDI). I thought about a few potential ways to measure the diversity of languages in a country, and ulimately settled on this definition: the percentage probability that two random residents of a given country have different native languages. Compared to other potential measurements (such as the popularity of the most common language within a country), this definition for the LDI has the advantage of taking into account every language spoken in a country, while still being easy to visualize.
Computing the LDI is pretty straightforward. Given a country with population P and n languages, with L1, L2, ..., Ln speakers, respectively, the LDI of the country is:
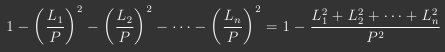
Now, if I had bothered to do a Google search at this point, I would have found out that there actually is such a thing as a Linguistic Diversity Index (also known as Greenberg’s diversity index), and, moreover, it's defined more or less the same way that I defined it (namely, the probability that any two people of the country selected at random would have different mother tongues), and the data listed on the Wikipedia page is very close to what I ultimately obtained, as it was calculated using similar data. But I didn't realize that an LDI already existed at the time, and so I ended up essentially duplicating the existing work on the topic.
Scraping Ethnologue Data with Mechanize
Let me take some time to show how I collected the data for the LDI. If you'd rather just skip ahead to the pretty charts, go right ahead. I won't be mad.
Still here? Awesome.
In order to calculate the LDI, I needed to find the most accurate data possible on the number of speakers of different languages within each country, and so I turned to Ethnologue, a database of statistics on ~7000 languages. Each country's page in Ethnologue looks like this (with the red boxes indicating the numbers that I want to extract):

Doing this by hand would be incredibly tedious, so I needed to find a way to scrape all of the country pages on Ethnologue. I wasn't sure what the best way to do this in Ruby would be, so I asked my trusty assistant, howdoi:
> howdoi scrape web page in ruby
take a look at this library http://mechanize.rubyforge.org/Ah, excellent! Mechanize does just what I want, and has spiffy syntax to boot (for example, languages = country_page / "#main table p" literally divides the page into an array of sections matched by the CSS selector #main table p). The full script that I used to gather all of the data I needed clocks in at around 50 lines, and the trickiest bit was coming up with the appropriate regexes to extract the right things:
require 'mechanize'
agent = Mechanize.new
language_regex = Regexp.new(/]\r\n\t\t\t\t\t\t([0-9,]*)(\.| )/)
index_page = agent.get('http://www.ethnologue.com/country_index.asp?place=all')
index_page.links_with(:href => /show_country.asp/).each do |country_link|
country = country_link.text().strip()
speakers = []
country_page = agent.get('http://www.ethnologue.com/' + country_link.href)
# get language speakers from table
languages = country_page / "#main table p"
if languages.length() > 0
speakers += languages.map do |l|
language_regex.match(l.children()[0].content())[1].gsub(',','').to_i rescue 0
end
end
# get immigrant language speakers
description = (country_page / "#main blockquote")[0].children()[0].content()
immigrant_languages_description = description.scan(/Immigrant languages:.*?\./)[0]
if immigrant_languages_description
immigrant_languages = immigrant_languages_description.scan(/\(([0-9,]*)\)/)
.map{|x| x[0].gsub(',','').to_i}
speakers += immigrant_languages
end
# get language speakers from subpages (if any)
country_page.links_with(:href => /show_country.asp/).each do |subpage_link|
subpage = agent.get('http://www.ethnologue.com/' + subpage_link.href)
subpage_languages = subpage / "#main table p"
if subpage_languages.length() > 0
subpage_speakers = subpage_languages.map do |l|
language_regex.match(l.children()[0].content())[1].gsub(',','').to_i rescue 0
end
end
speakers += subpage_speakers
end
# compute diversity index
total_speakers = speakers.inject(0, &:+)
diversity_index = if total_speakers > 0
(1 - speakers.map{|x| x**2}.inject(0, &:+).to_f / total_speakers ** 2) * 100
else
"Insufficient data for meaningful answer"
end
puts "#{country.ljust(40)}\t#{diversity_index}"
endNote that I make a few simplifying assumptions here. For one thing, I didn't use Ethnologue's given value for the total population of each country, but rather set P = L1 + L2 + ... + Ln. This was important because I've noted Ethnologue's total population values to typically be more out of date than the language data, and I didn't want LDI values below zero, which could occur if, say, L1 > P. Ethnologue language data is also imperfect - for example, some minor languages don't have their speaker count listed - but I assumed that the data was accurate enough as a whole for my computed LDI values to be meaningful.
Results
After running the script, I got these results. But raw data is boring. Let's make it into a map!
There's some interesting patterns that can be seen from the map. It appears that countries in Sub-Saharan Africa and South and Southeast Asia tend to have the highest rates of linguistic diversity (Papua New Guinea is at the very top, with over 600 different languages spoken and a diversity index of 99.03). All in all, thoughout the world, diversity appears to be the norm, rather than homogeneity: even Europe has its fair share of high-LDI countries (admittedly, a lot of this is made murky by the question of what is a language and what is a dialect).
Now I finally have all of the data that I need to test my friend's hypothesis about the relationship between language diversity and affluence. Using GDP (PPP) per capita data from the World Bank, I get the following plot:
There is a weak negative correlation (ρ = -0.247), suggesting that the relationship between language diversity and affluence is tenuous at best. Interestingly, while there are a great deal of countries that are both very poor and highly linguistically diverse, 7 of the 9 wealhiest countries (with the exceptions being Norway and the United States) all have LDI in the 48-78 range, perhaps suggesting that some level of linguistic diversity is economically useful in establishing a nation as a trade hub. Of course, correlation does not imply causation, and there aren't many conclusions that can reasonably be drawn from this chart without more outside information.
Conclusion
All told, this was a fun little project. It was unfortunate that I only found out later that the LDI already exists, and so my data collection was unnecessary, but it was nice to get some experience in scraping data, and I think that I've come up with some novel ways to present language diversity data. In the end, I feel that there is certainly room for more research to be done in the interconnection between the linguistic and economic spheres of countries.
Comments
blog comments powered by Disqus